01 · Why this matters
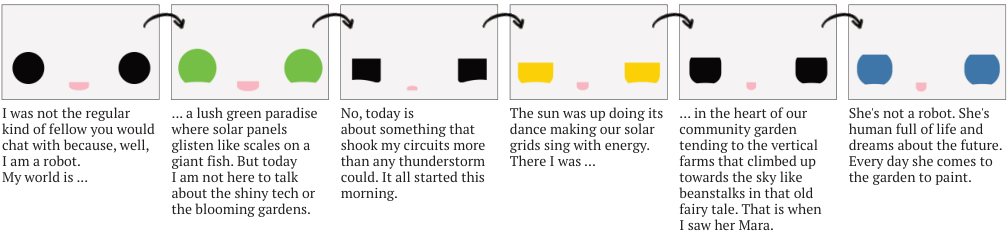
Context-aware expressions make the face feel alive instead of pre-scripted.
Existing systems usually depend on hand-tuned expression libraries or large training corpora that do not transfer cleanly across robots and interaction settings.
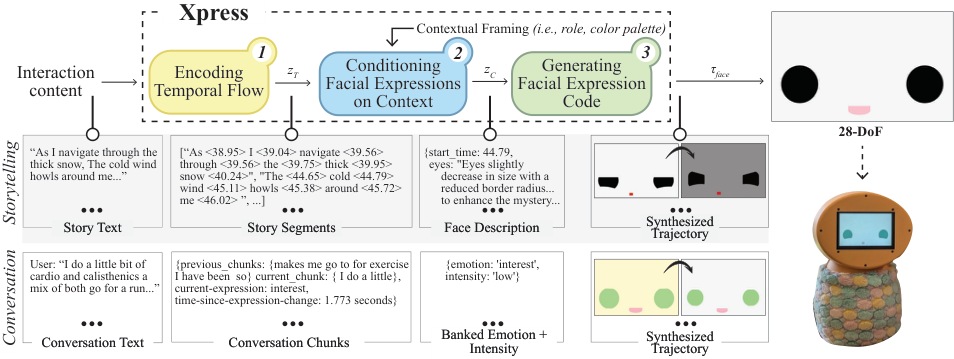
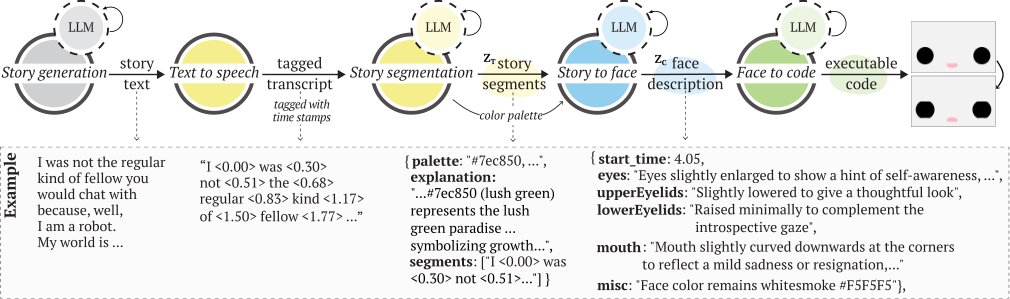
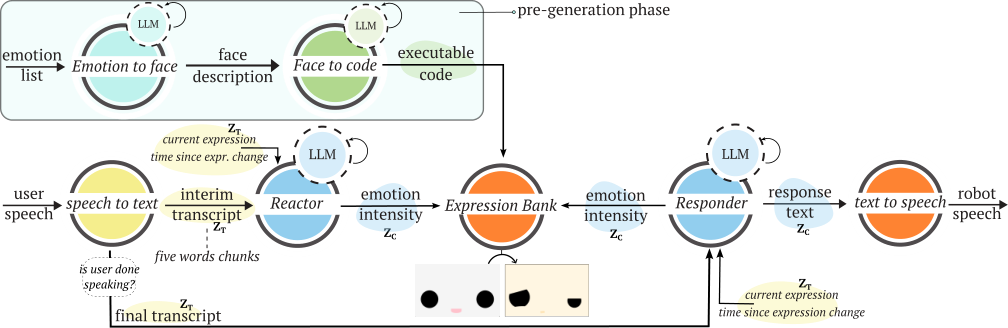
Xpress takes a lighter path: it uses language models to segment dialogue, interpret socio-emotional context, and generate executable face behavior on demand without retraining.
"It didn't feel like a robot was telling me a story. It felt closer to a human being."
Adult participant — storytelling study
Problem Static faces
Most social robots still rely on a handful of expressions that repeat regardless of timing, dialogue, or emotional nuance.
Approach LM pipeline
Xpress segments interaction flow, conditions on context, and synthesizes executable expression trajectories instead of selecting canned poses.
Why it scales No retraining
The system works as a generative layer that can be pointed at new interaction content without building a new expression dataset for each deployment.